My previous post talked a little bit about new functionality from (new and updated) ec2-related modules in the Ansible 1.0 release. In this post I’ll go through the practical example of launching multiple instances with the ec2 module and then configuring them with a workload. In this case the workload will be the Eucalyptus User Console 🙂
For those who are unfamiliar with ansible, check out the online documentation here. The documentation itself is in a pretty good order for newcomers, so make sure to take it step by step to get the most out of it. Once you’ve finished you’ll then come to realise how flexible it is but hopefully also how *easy* it is.
To launch my instances and then configure them, I’m going to use a playbook. For want of a better explanation a playbook is a yaml formatted file containing a series of tasks which orchestrate a configuration or deployment process. The playbook can contain multiple plays, these are separate sections of the playbook (perhaps for logical reasons) which target specific hosts or groups of hosts.
Getting Started
First up, get hold of ansible! We’ll clone from GitHub in this example, see here for alternatives. You need to make sure you have Ansible release 1.0 or the latest devel snapshot.
$ git clone git://github.com/ansible/ansible.git
$ cd ./ansible
$ source ./hacking/env-setup
Next, we need to create a hosts file. This hosts file can reside anywhere and be specified with the “-i” option when running Ansible. By default Ansible will look in /etc/ansible/hosts, so lets create this file.
$ touch /etc/ansible/hosts
Our playbook will depend on a single entry for localhost, so add the following to this file:
[local]
localhost
This assumes you have a localhost entry in your systems /etc/hosts file.
Try it out
Now we’re ready to really get started. Before we create our playbook, lets verify that the environment is setup and working correctly. Choose a system on which you have a login and SSH access and lets try and retrieve some facts by using Ansible in task execution mode.
In this example I’m using host “prc6” onto which I’ve copied my public SSH key. This host has sudo configured and I have the appropriate permissions for root in the sudoers file. Ansible can take this into account with the appropriate switches:
# ansible prc6 -m setup -s -K
Lets break that down:
ansible prc6 # run against this host, this could also be a host group found in /etc/ansible/hosts
-m setup # run the setup module on the remote host
-s -K # tell ansible I'm using sudo and ask ansible to prompt me for my sudo password
Running this command returns a load of in-built facts from the setup module about the remote host:
prc6 | success >> {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"10.104.1.130"
],
"ansible_all_ipv6_addresses": [
"fe80::ea9a:8fff:fe74:13c2"
],
"ansible_architecture": "x86_64",
"ansible_bios_date": "06/22/2012",
"ansible_bios_version": "2.0.3",
"ansible_cmdline": {
"KEYBOARDTYPE": "pc",
"KEYTABLE": "us",
"LANG": "en_US.UTF-8",
"SYSFONT": "latarcyrheb-sun16",
"crashkernel": "129M@0M",
"quiet": true,
"rd_LVM_LV": "vg01/lv_root",
"rd_MD_UUID": "1b27ae4a:6c4a8a77:6f718721:d335bf17",
"rd_NO_DM": true,
"rd_NO_LUKS": true,
"rhgb": true,
"ro": true,
"root": "/dev/mapper/vg01-lv_root"
}, [...cont]
If we were using a playbook, we could use these gathered facts in our configuration jobs. Neat huh? An example might be some kind of conditional execution, in pseudo:
if bios_version <= 2.0.3 then update firmware
This gives you just an extremely small idea of how ansible can be used as a configuration management engine. Better still, modules are highly modular (wierd that?!) and can be written in pretty much any language, so you could write your own module to gather whatever facts you might want. We’re planning a Eucalyptus configuration module in the future 🙂
Anyhow, I digress …..
Playbook
With ansible working nicely, lets start writing our playbook. With our next example we want to achieve the following aim:
- Launch 3 instances in ec2/Eucalyptus using Ansible
Firstly, we need to address dependencies. With 1.0, the ec2 module was ported to boto so install the python-boto and m2crypt packages on your local system:
$ yum install python-boto m2crypt
Next up, get the credentials for your EC2 or Eucalyptus cloud. If you’re using Eucalyptus, source the eucarc as the ec2 module will take the values for EC2_ACCESS_KEY, EC2_SECRET_KEY and EC2_URL from your environment. If you’re wanting to use ec2, just export your access and secret key, boto knows the endpoints:
# export EC2_SECRET_KEY=XXXXXX
# export EC2_ACCESS_KEY=XXXXXX
At this point you might want to try using euca2ools or ec2-tools to interact with your cloud, just to check your credentials 🙂
Onto the action! Below is a playbook broken up into sections, you can see the whole thing here as eucalyptus-user-console-ec2.yml. Save this as euca-demo.yml:
- name: Stage instance # we name our playbook
hosts: local # we want to target the “local” host group we defined earlier in this post
connection: local # we want to run this action locally on this host
user: root # we want to run as this user
gather_facts: false # since we're running locally, we don't want to gather system facts (remember the setup module we tested?)
vars: # here we define some play variables
keypair: lwade # this is our keypair in ec2/euca
instance_type: m1.small # this is the instance type we want
security_group: default # our security group
image: emi-048B3A37 # our image
count: 3 # how many we want to launch
tasks: # here we begin the tasks section of the playbook, which is fairly self explanatory :)
- name: Launch instance # name our tasks
local_action: ec2 keypair=$keypair group=$security_group instance_type=$instance_type image=$image count=$count wait=true # run the ec2 module locally, with the parameters we want
register: ec2 # register (save) the output for later use
- name: Itemised host group addition
local_action: add_host hostname=${item.public_ip} groupname=launched # here we add the public_ip var from the list of ec2.instances to a host group called "launched", ready for the next play
with_items: ${ec2.instances}
You could try running this now. Run with:
# ansible-playbook euca-demo.yml
Once complete, take a look at your running instances:
# euca-describe-instances
RESERVATION r-48D14305 230788055250 default
INSTANCE i-127F4992 emi-048B3A37 10.104.7.12 172.25.26.172 running admin 2 m1.small 2013-02-05T14:59:36.095Z uno-cluster eki-38B93991 eri-EC703A1C monitoring-disabled 10.104.7.12 172.25.26.172 instance-store
INSTANCE i-244B42C9 emi-048B3A37 10.104.7.10 172.25.26.173 running admin 0 m1.small 2013-02-05T14:59:36.044Z uno-cluster eki-38B93991 eri-EC703A1C monitoring-disabled 10.104.7.10 172.25.26.173 instance-store
INSTANCE i-FADD43E0 emi-048B3A37 10.104.7.11 172.25.26.169 running admin 1 m1.small 2013-02-05T14:59:36.076Z uno-cluster eki-38B93991 eri-EC703A1C monitoring-disabled 10.104.7.11 172.25.26.169 instance-store
Now we want a playbook (play) section to deal with the configuration of the instance. We define the next play in the same file. Remember this entire file is available here.
- name: Configure instance
hosts: launched # Here we use the hostgroup from the previous play; all of our instances
user: root
gather_facts: True # Since these aren't local actions, I've left facter gathering on.
vars_files: # Here we demonstrate an external yaml file containing variables
- vars/euca-console.yml
tasks: # Begin the tasks
- name: Ensure NTP is up and running # Using the "service" module to check state of ntpd
action: service name=ntpd state=started
- name: Downloads the repo RPMs # download the list of repo RPM's we need
action: get_url url=$item dest=/tmp/ thirsty=yes
with_items:
- http://downloads.eucalyptus.com/software/eucalyptus/${euca_version}/rhel/6/x86_64/eucalyptus-release-${euca_version}.noarch.rpm
- http://downloads.eucalyptus.com/software/eucalyptus/${euca_version}/rhel/6/x86_64/epel-release-6.noarch.rpm
- http://downloads.eucalyptus.com/software/eucalyptus/${euca_version}/rhel/6/x86_64/elrepo-release-6.noarch.rpm
tags:
- geturl
- name: Install the repo RPMs # Install the RPM's for the repos
action: command rpm -Uvh --force /tmp/$item
with_items:
- eucalyptus-release-${euca_version}.noarch.rpm
- epel-release-6.noarch.rpm
- elrepo-release-6.noarch.rpm
- name: Install Eucalyptus User Console # Use the yum module to install the eucalyptus-console package
action: yum pkg=eucalyptus-console state=latest
- name: Configure User Console Endpoint # Here we use the lineinfile module to make a substitutions based on a regexp in the configuration file
action: lineinfile dest=/etc/eucalyptus-console/console.ini state=present regexp=^clchost line=clchost:" ${clchost}"
- name: Configure User Console Port
action: lineinfile dest=/etc/eucalyptus-console/console.ini state=present regexp=^uiport line=uiport:" ${port}"
- name: Configure User Console Language
action: lineinfile dest=/etc/eucalyptus-console/console.ini state=present regexp=^language line=language:" ${lang}"
- name: Restart Eucalyptus User Console # With the config changed, use the service module to restart eucalyptus-console
action: service name=eucalyptus-console state=restarted
There we have it. The playbook with two distinct plays is complete; one play to launch the instances and another to configure them. Lets run our playbook and observe the results.
To run a playbook, you use the ansible-playbook command with much the same options as with ansible (task execution mode). Since our instances we launch will need a private key, we specify this as part of the command:
# ansible-playbook euca-demo.yml --private-key=/home/lwade/.euca/mykey.priv -vvv
The -vvv switch gives extra verbose output.
As ansible goes off and configures the systems in parallel you’ll see this sort of output, indicating whether a task has been successful:
TASK: [Ensure NTP is up and running] *********************
<10.104.7.10> ESTABLISH CONNECTION FOR USER: root on PORT 22 TO 10.104.7.10
<10.104.7.11> ESTABLISH CONNECTION FOR USER: root on PORT 22 TO 10.104.7.11
<10.104.7.12> ESTABLISH CONNECTION FOR USER: root on PORT 22 TO 10.104.7.12
<10.104.7.10> EXEC /bin/sh -c 'mkdir -p $HOME/.ansible/tmp/ansible-1360077064.27-8382619657571 && echo $HOME/.ansible/tmp/ansible-1360077064.27-8382619657571'
<10.104.7.11> EXEC /bin/sh -c 'mkdir -p $HOME/.ansible/tmp/ansible-1360077064.27-166172056795312 && echo $HOME/.ansible/tmp/ansible-1360077064.27-166172056795312'
<10.104.7.12> EXEC /bin/sh -c 'mkdir -p $HOME/.ansible/tmp/ansible-1360077064.3-30210459423135 && echo $HOME/.ansible/tmp/ansible-1360077064.3-30210459423135'
<10.104.7.10> REMOTE_MODULE service name=ntpd state=started
<10.104.7.11> REMOTE_MODULE service name=ntpd state=started
<10.104.7.10> PUT /tmp/tmptDgeMW TO /root/.ansible/tmp/ansible-1360077064.27-8382619657571/service
<10.104.7.11> PUT /tmp/tmpBF7ekS TO /root/.ansible/tmp/ansible-1360077064.27-166172056795312/service
<10.104.7.12> REMOTE_MODULE service name=ntpd state=started
<10.104.7.12> PUT /tmp/tmpA49v9F TO /root/.ansible/tmp/ansible-1360077064.3-30210459423135/service
<10.104.7.10> EXEC /bin/sh -c '/usr/bin/python /root/.ansible/tmp/ansible-1360077064.27-8382619657571/service; rm -rf /root/.ansible/tmp/ansible-1360077064.27-8382619657571/ >/dev/null 2>&1'
<10.104.7.11> EXEC /bin/sh -c '/usr/bin/python /root/.ansible/tmp/ansible-1360077064.27-166172056795312/service; rm -rf /root/.ansible/tmp/ansible-1360077064.27-166172056795312/ >/dev/null 2>&1'
<10.104.7.12> EXEC /bin/sh -c '/usr/bin/python /root/.ansible/tmp/ansible-1360077064.3-30210459423135/service; rm -rf /root/.ansible/tmp/ansible-1360077064.3-30210459423135/ >/dev/null 2>&1'
ok: [10.104.7.10] => {"changed": false, "name": "ntpd", "state": "started"}
ok: [10.104.7.12] => {"changed": false, "name": "ntpd", "state": "started"}
ok: [10.104.7.11] => {"changed": false, "name": "ntpd", "state": "started"}
We see that the task to ensure ntpd is running has been completed successfully. At the end of all the plays we get a recap:
PLAY RECAP *********************
10.104.7.10 : ok=9 changed=5 unreachable=0 failed=0
10.104.7.11 : ok=9 changed=5 unreachable=0 failed=0
10.104.7.12 : ok=9 changed=5 unreachable=0 failed=0
localhost : ok=2 changed=2 unreachable=0 failed=0
This demonstrates tasks completed successfully and those which changed something on the system.
Let’s see if it worked, point your web browser to https://public_ip:8888 of one of your instances (e.g. https://10.104.7.12:8888):
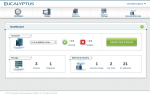
Job done! Maybe next you could try putting a load balancer in front of these three instances? 🙂
Hopefully this was a good taste of deploying applications into the cloud with the help of Ansible. I’ll continue to write with further examples of workloads over the next couple of months and will put this information into the Eucalyptus GitHub wiki.
EDIT – If people see value in a playbook repository for generic workloads and other deployment examples on EC2/Eucalyptus, let me know. I’m sure we can get a common repo setup 🙂

